
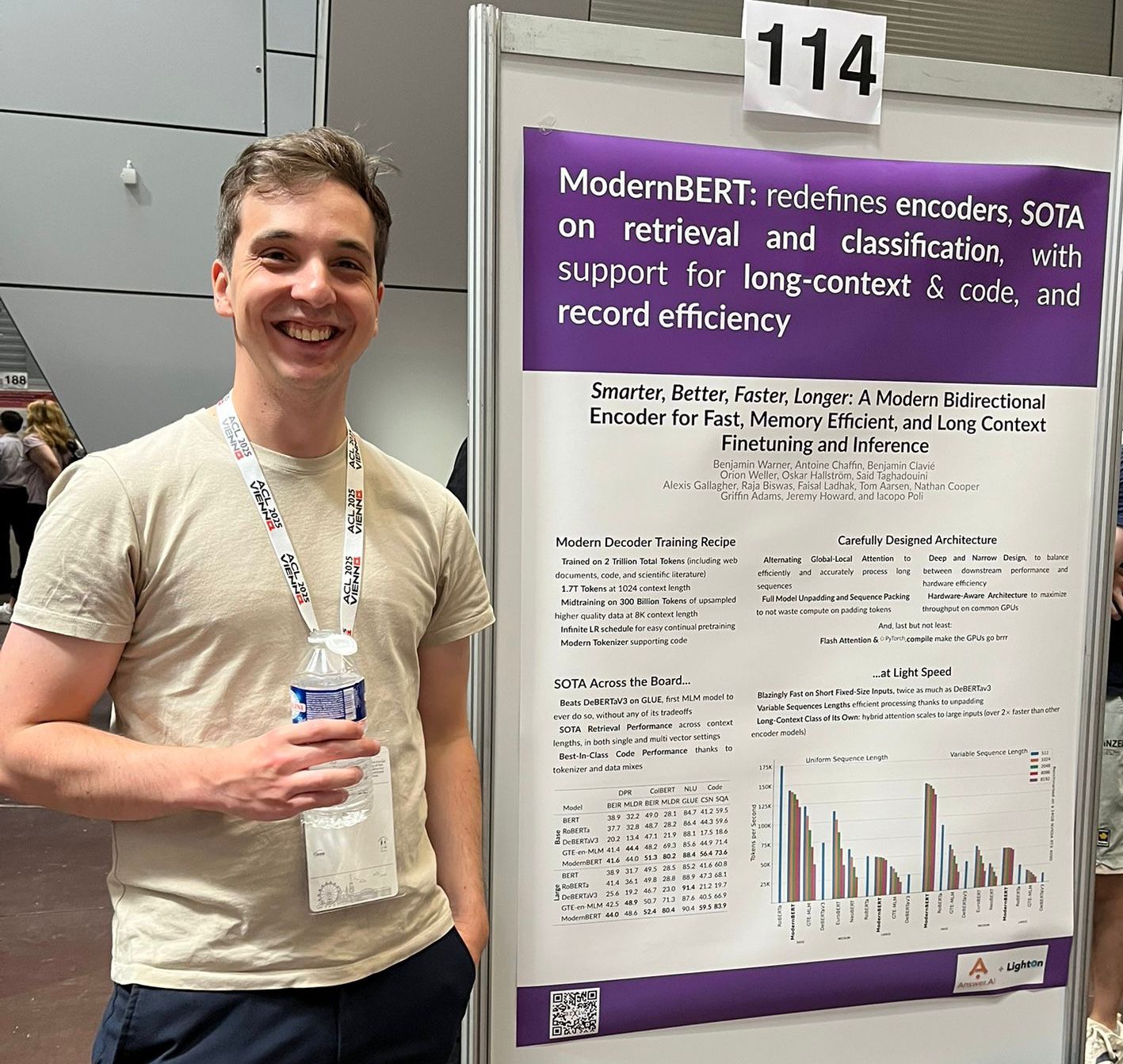










PyLate
Python
We introduce PyLate, a flexible library to train and experiment with ColBERT models. ColBERT models are encoders used for retrieval that exhibit strong performance, especially on out-of-domain data. Yet, despite growing interest, few models are being released. PyLate aims to fill this gap by providing a modular library built on the widely-used sentence-transformers framework, making it both accessible and efficient!






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}